Outils pour utilisateurs
Ceci est une ancienne révision du document !
Table des matières
Comment fonctionne un logiciel de compression de données
Un logiciel de compression de données permet de rassembler et réduire la taille d'un ou plusieurs fichiers pour, par exemple, pouvoir les stocker sur des périphériques de stockage disposant de peu d'espace (clé USB, disquette, carte SD, etc…) ou encore, pour pouvoir les transmettre plus rapidement à travers un réseau (FTP, mail, etc…).
Le logiciel doit ensuite, pouvoir reconstituer les fichiers à l'identique (en conservant l'arborescence des fichiers, les droits d'accès etc…). On parle ici, de compression sans pertes.
Dans le cas d'images ou de sons, l'œil ou l'oreille ne pourra pas perçevoir tous les détails du fichier. Il est alors possible de le modifier de manière plus ou moins importante pour baisser sa qualité et donc réduire sa taille, sans que cela ne soit visible pour un humain. On parle alors de compression avec pertes.
Parmi les logiciels de compression de données les plus connus, on retrouve par exemple 7-zip, Winrar ou WinZip.

La compression de données consiste à appliquer un algorithme à une suite de bits, pour obtenir une nouvelle suite dans l'idéal, plus courte.
La compression sans pertes
Dans le cas d'une compression sans pertes, aucune information n'est modifiée dans le fichier, elles sont justes réécrites de manière plus condensée.
Il n'existe à ce jour, aucun algorithme de compression sans perte permettant de compresser efficacement n'importe quel fichier. En effet, certains algorithme peuvent être très efficaces avec certains fichiers tout en augmentant la taille de certains autres. C'est pour cela qu'il existe plusieurs algorithmes, adaptés à des types de données différents (images bitmap, texte, fichier audio etc…)
Voici quelques exemples d'algorithmes de compression sans pertes
RLE (run-length encoding)
le codage RLE consiste à remplacer une suite de bits identiques par le nombre de répétitions suivi de la suite répétée.
exemple:
nous avons la suite de bits suivante: 1001100110011010101010100000000010011001
nous pouvons définir A=1001 B=1010 C=0000
et réécrire la suite de cette façon: AAABBBCCAA ;
en appliquant l'algorithme précédent, on obtient : 3A3B2C2A
Nous avons donc bien réduit la taille de la suite initiale.
Cependant, dans le cas ou la suite aurait une forme ABAB , la suite finale serait 1A1B1A1B ce qui est 2 fois plus long.
Cet algorithme sera donc plus adapté à des images bitmap possèdant peu de couleurs différentes qu'à des fichiers contenant du texte car la probabilité de trouver des suites de bits identiques sera alors plus élevée.
Le codage de Huffman
Cet algorithme consiste à remplacer dans un fichier, chaque octet par un code qui lui correspond, tout en attribuant un code plus court aux octets apparaissant plus régulièrement.
Pour définir le code d'un octet, on utilise un arbre.
exemple:
nous avons la suite d'octets suivante (sous forme de chaîne de caracètres pour simplifier la compréhension): ABRACADABRA . En considérant que chaque caractère prends 8bits en mémoire, on a une chaîne de 88bits.
On compte alors le nombre d'apparitions de chaque caractère:
A:5,
B:2,
R:2,
C:1,
D:1
L'arbre correspondant à cette chaîne de caractères sera le suivant:
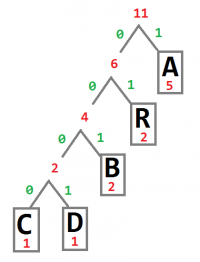
(Les chiffres en rouge correspondent au nombre d'occurences de chaque caractère )
Partant du haut et en lisant les chiffres en vert, on peut alors déterminer le code correspondant à chaque caractère.
A:1,
R:01,
B:001,
C:0000,
D:0001
On a donc bien un code plus petit sur les caractères apparaîssant le plus dans la chaîne.
La chaîne, une fois compressée sera donc écrite de cette manière : 1 001 01 1 0000 1 0001 1 001 01 1 ce qui donne une taille de 23bits.
La chaîne compressée est donc bien plus courte que l'originale.
Le problème de cet algorithme est qu'il faut, pour pouvoir décompresser les donnée, écrire la table des correspondances caractère-code au début du fichier, qui peut être volumineuse.
La compression sans pertes
Dans le cas d'une compression avec pertes, le nombre d'informations est réduit. Pour éviter que cette dégradation ne soit perçue, on se base ici sur les caractéristiques des systèmes visuel et auditif humains.
Les algorithmes de compression avec pertes ne peuvent pas être utilisés pour compresser du texte au risque de le rendre illisible.
Dans le cas d'une image, on pourra procèder à un sous-échantillonnage: l'œil perçevant plus la luminosité que les couleurs, il sera possible de supprimer une grande partie des informations dédiées aux couleurs dans l'image sans que le résultat le soit visible.
Dans le cas d'un fichier audio, on pourra par exemple, supprimer les fréquences jouées avec une trop faible intensité sonore pour être au dessus du seuil d'audibilité en présence d'un autre son masquant.
Il existe d'autres algorithmes de compression avec pertes plus complexes comme par exemple, la compression par ondelettes qui consiste à décomposer une image en un ensemble d'autres images de plus faible résolution(très efficace sur les images), ou encore, la transformée en cosinus discrète.
Sources
Outils de la page
