Outils pour utilisateurs
Ceci est une ancienne révision du document !
Table des matières
Algorithme des k plus proche voisins:
Introduction:
L'algorithme des k plus proches voisins appartient à la famille des algorithmes d'apprentissage automatique (machine learning). C'est un algorithme simple a appréhender, il permet apprentissage supervisé qui permet de classer de nouvelles données. Les GAFAM utilisent également les données concernant les utilisateurs afin de “nourrir” des algorithmes de machine learning qui permettrons à des sociétés d'en savoir toujours plus sur nous et ainsi de mieux cerner nos “besoins” en termes de consommation. Ce type d'algorithme sont par exemple utilisé pour classer différentes espèces d'arbres par exemple.
Principe de l'algorithme:
L'algorithme des k plus proche voisins ne nécessite pas de phase d'apprentissage (à proprement parlé), il faut juste stocker le jeu de données d'apprentissage. Soit un ensemble E contenant n données labelisées: E={(yi,xi)} avec i compris entre 1 et n, où yi correspond à la classe de la donnée i et où le vecteur xi de dimension p(xi=(x1i,x2i,…,xpi)) représente les variables prédictrices de la donnée i. Soit une donnée u qui n'appartient pas à E et qui ne possède pas de label (u est uniquement caractérisée par un vecteur xu de dimension p). Soit d une fonction qui renvoie la distance entre la donnée u et une donnée quelconque appartenant à E. Soit un entier k inférieur ou égal à n. Voici le principe de l'algorithme de k plus proches voisins:
- On calcule les distances entre la donnée u et chaque donnée appartenant à E à l'aide de la fonction d.
- On retient les k données du jeu de données E les plus proches de u.
- On attribue à u la classe qui est la plus fréquente parmi les k données les plus proches.
Il est possible d'utiliser différents types de distance si souhaité.
Etude d'un exemple:
Les données:
Par exemple pour un jeu de donnée s'appelant “iris de Fisher” qui est composé de 50 entrées et pour chaque entrée nous avons:
- La longueur des sépales (en cm)
- La largeur des sépales (en cm)
- La longueur des pétales (en cm)
- La largeur des pétales (en cm)
- L'espèce d'Iris
Il est possible de télécharger ces données au format csv.
Ensuite il faut les modifier à l'aide d'un tableur:
- Nous supprimons les colones qui ne nous intéresse pas afin de garder seulement celles qui nous intéresse.
- Il faut égallement encoder les espèces avec des chiffres (0,1,2,…)
Bibliothèques Python utilisées:
Nous utiliserons 3 bibliothèques Python:
- Pandas qui va nous permettre d'importer les données issues du fichier csv
- Matplotlib qui va nous permettre de visualiser les données
- Scikit-learn qui propose une implémentation de l'algorithme des k plus proches voisins
Ces bibliothèques sont facilement installables notamment en utilisant la distribution Anaconda.
Première visualisation des données:
Une fois que le fichier csv est modifié, il est possible d'écrire un programme permettant de visualiser les données sous la forme de graphique:
import pandas import matplotlib.pyplot as plt iris=pandas.read_csv("iris.csv") x=iris.loc[:,"petal_length"] y=iris.loc[:,"petal_width"] lab=iris.loc[:,"species"] plt.axis('equal') plt.scatter(x[lab == 0], y[lab == 0], color='g', label='setosa') plt.scatter(x[lab == 1], y[lab == 1], color='r', label='versicolor') plt.scatter(x[lab == 2], y[lab == 2], color='b', label='virginica') plt.legend() plt.show()
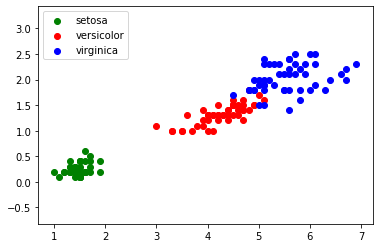 FIGURE 1 - Représentation graphique des données
FIGURE 1 - Représentation graphique des données
Utilisation de l'algorithme des k plus proches voisins:
Le graphique ci-dessus (FIGURE 1) montre que les 3 classes (Iris stetosa, Iris virginica, Iris versicolor) sont relativement bien séparées. On peut ajouter une données non labellisée n'appartenant pas à l'ensemble d'origine (FIGURE 2):
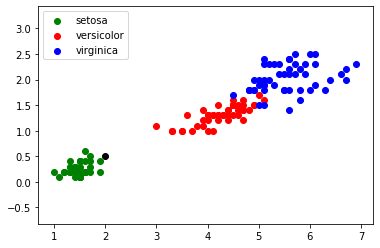 FIGURE 2 - Ajout d'une donnée non labellisée
FIGURE 2 - Ajout d'une donnée non labellisée
Dans l'exemple ci-dessus (FIGURE 2), nous n'aurons aucune difficultés à déterminer l'espèce d'Iris qui a été ajouté au jeu de données. Dans certains cas, il est un peu plus difficile de se prononcer “au premier coup d'oeil” (FIGURE 3):
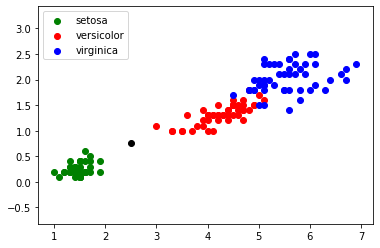 FIGURE 3 - Cas plus difficile
FIGURE 3 - Cas plus difficile
A partir de l'exemple ci-dessus (FIGURE 3), il faut utiliser une méthode pour traiter ce genre de cas litigieux. Nous allons pour ce faire, utiliser l'algorithme des k plus proches voisins:
- On calcule la distance entre nos points et chaque points issu du jeu de données “Iris”
- On sélectionne uniquement les k distances les plus petites
- Parmi les k plus proches voisins, on détermine quelle est l'espèce majoritaire?
- On associe à notre “Iris mystère” cette espèce “majoritaire parmi les k plus proches voisins”
Dans l'exemple évoqué ci-dessus, nous obtenons graphiquement:
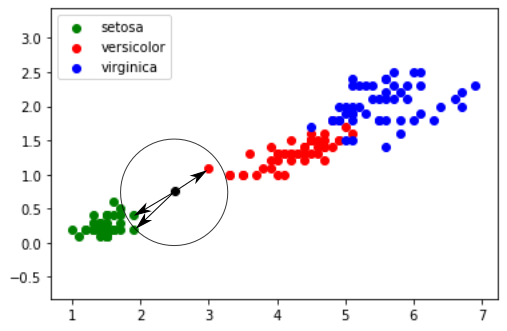 FIGURE 4 - Ici les 3 plus proches voisins
FIGURE 4 - Ici les 3 plus proches voisins
Un Iris ayant une largeur de pétale égale à 0.75 cm et une longueur de pétale égale à 2.5 cm a une “forte” probabilité d'appartenir à l'espèce setosa.
Utilisation de scikit-learn:
La bibliothèque Python scikit-learn propose un grand nombre d'algorithmes lié à l'apprentissage automatique. Parmi tout ces algorithmes, scikit-learn propose l'algorithme des k plus proches voisins. Voici un programme Python permettant de résoudre le problème évoqué ci-dessus:
import pandas import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier #traitement CSV iris=pandas.read_csv("iris.csv") x=iris.loc[:,"petal_length"] y=iris.loc[:,"petal_width"] lab=iris.loc[:,"species"] #fin traitement CSV #valeurs longueur=2.5 largeur=0.75 k=3 #fin valeurs #graphique plt.scatter(x[lab == 0], y[lab == 0], color='g', label='setosa') plt.scatter(x[lab == 1], y[lab == 1], color='r', label='virginica') plt.scatter(x[lab == 2], y[lab == 2], color='b', label='versicolor') plt.scatter(longueur, largeur, color='k') plt.legend() #fin graphique #algo knn d=list(zip(x,y)) model = KNeighborsClassifier(n_neighbors=k) model.fit(d,lab) prediction= model.predict([[longueur,largeur]]) #fin algo knn #Affichage résultats txt="Résultat : " if prediction[0]==0: txt=txt+"setosa" if prediction[0]==1: txt=txt+"virginica" if prediction[0]==2: txt=txt+"versicolor" plt.text(3,0.5, f"largeur : {largeur} cm longueur : {longueur} cm", fontsize=12) plt.text(3,0.3, f"k : {k}", fontsize=12) plt.text(3,0.1, txt, fontsize=12) #fin affichage résultats plt.show()
Nous obtenons le résultat suivant (FIGURE 5):
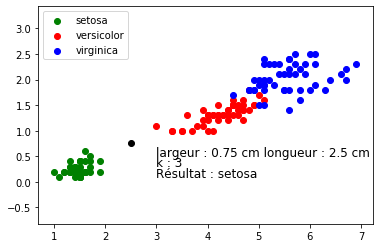 FIGURE 5 - A l'aide de scikit-learn
FIGURE 5 - A l'aide de scikit-learn
Il est également possible de modifier le programme ci-dessus afin d'étudier les changements induits par la modification du paramètre k en gardant toujours les mêmes valeurs de largeur et de longueur ou encore de changer les valeurs de longueur et de largeur.
Outils de la page
