Outils pour utilisateurs
Ceci est une ancienne révision du document !
Table des matières
**Algorithme des k plus proche voisins:**
__Introduction:__
L'algorithme des k plus proches voisins appartient à la famille des algorithmes d'apprentissage automatique (machine learning). C'est un algorithme simple a appréhender. Les apprentissages automatique ne date pas d'hier et ont connu un fort regain d'intérêt au début des années 2000, notamment grâce à la quantité de données disponibles sur internet. C'est un algorithme d'apprentissage supervisé qui permet de classer de nouvelles données mais qui permet également d'utiliser cet algorithme a des fins de régression (non abordé dans le programme). Les GAFAM utilisent également les données concernant les utilisateurs afin de “nourrir” des algorithmes de machine learning qui permettrons à des sociétés d'en savoir toujours plus sur nous et ainsi de mieux cerner nos “besoins” en termes de consommation.
__Principe de l'algorithme:__
L'algorithme des k plus proche voisins ne nécessite pas de phase d'apprentissage (à proprement parlé), il faut juste stocker le jeu de données d'apprentissage. Soit un ensemble E contenant n données labelisées: E={(yi,xi)} avec i compris entre 1 et n, où yi correspond à la classe de la donnée i et où le vecteur xi de dimension p(xi=(x1i,x2i,…,xpi)) représente les variables prédictrices de la donnée i. Soit une donnée u qui n'appartient pas à E et qui ne possède pas de label (u est uniquement caractérisée par un vecteur xu de dimension p). Soit d une fonction qui renvoie la distance entre la donnée u et une donnée quelconque appartenant à E. Soit un entier k inférieur ou égal à n. Voici le principe de l'algorithme de k plus proches voisins:
- On calcule les distances entre la donnée u et chaque donnée appartenant à E à l'aide de la fonction d.
- On retient les k données du jeu de données E les plus proches de u.
- On attribue à u la classe qui est la plus fréquente parmi les k données les plus proches.
Il est possible d'utiliser différents types de distance si souhaité.
__Etude d'un exemple:__
Les données:
Par exemple pour un jeu de donnée s'appelant “iris de Fisher” qui est composé de 50 entrées et pour chaque entrée nous avons:
- La longueur des sépales (en cm)
- La largeur des sépales (en cm)
- La longueur des pétales (en cm)
- La largeur des pétales (en cm)
- L'espèce d'Iris
Il est possible de télécharger ces données au format csv.
Ensuite il faut les modifier à l'aide d'un tableur:
- Nous supprimons les colones qui ne nous intéresse pas afin de garder seulement celles qui nous intéresse.
- Il faut égallement encoder les espèces avec des chiffres (0,1,2,…)
Bibliothèques Python utilisées:
Nous utiliserons 3 bibliothèques Python:
- Pandas qui va nous permettre d'importer les données issues du fichier csv
- Matplotlib qui va nous permettre de visualiser les données
- Scikit-learn qui propose une implémentation de l'algorithme des k plus proches voisins
Ces bibliothèques sont facilement installables notamment en utilisant la distribution Anaconda.
Première visualisation des données:
Une fois que le fichier csv est modifié, il est possible d'écrire un programme permettant de visualiser les données sous la forme de graphique:
import pandas import matplotlib.pyplot as plt iris=pandas.read_csv("iris.csv") x=iris.loc[:,"petal_length"] y=iris.loc[:,"petal_width"] lab=iris.loc[:,"species"] plt.axis('equal') plt.scatter(x[lab == 0], y[lab == 0], color='g', label='setosa') plt.scatter(x[lab == 1], y[lab == 1], color='r', label='versicolor') plt.scatter(x[lab == 2], y[lab == 2], color='b', label='virginica') plt.legend() plt.show()
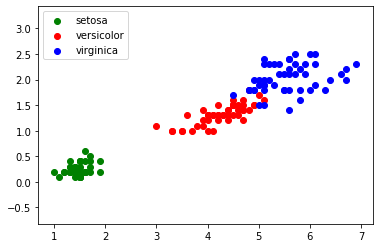 FIGURE 1 - Représentation graphique des données
FIGURE 1 - Représentation graphique des données
Utilisation de l'algorithme des k plus proches voisins:
Cet algorithme “k ppv” (en anglais “k nearest neighbors” : knn) est un algorithme d'apprentissage, qui prédit la classe d’un élément en fonction de la classe majoritaire de ses k plus proches voisins. Il permet par exemple de savoir grâce à des données, quelle fleur ça peut-être
Il fonctionne en deux parties, tout d'abord, il calcule la distance entre nos données recueillies et chaque donnée connues, et ensuite, on sélectionne uniquement les k distancent les plus petites (les k plus proches voisins)
parmi les k plus proches voisins, on détermine quel est le groupe de données majoritaires.
Exemple d'utilisation de l'algorithme k ppv en important des données sur des fleurs:
import pandas import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier #traitement CSV iris=pandas.read_csv("iris.csv") x=iris.loc[:,"petal_length"] y=iris.loc[:,"petal_width"] lab=iris.loc[:,"species"] #fin traitement CSV #valeurs longueur=2.5 largeur=0.75 k=3 #fin valeurs #graphique plt.scatter(x[lab == 0], y[lab == 0], color='g', label='setosa') plt.scatter(x[lab == 1], y[lab == 1], color='r', label='virginica') plt.scatter(x[lab == 2], y[lab == 2], color='b', label='versicolor') plt.scatter(longueur, largeur, color='k') plt.legend() #fin graphique #algo kppv d=list(zip(x,y)) model = KNeighborsClassifier(n_neighbors=k) model.fit(d,lab) prediction= model.predict([[longueur,largeur]]) #fin algo kppv #Affichage résultats txt="Résultat : " if prediction[0]==0: txt=txt+"setosa" if prediction[0]==1: txt=txt+"virginica" if prediction[0]==2: txt=txt+"versicolor" plt.text(3,0.5, f"largeur : {largeur} cm longueur : {longueur} cm", fontsize=12) plt.text(3,0.3, f"k : {k}", fontsize=12) plt.text(3,0.1, txt, fontsize=12) #fin affichage résultats plt.show()
Outils de la page
